Anticipating New KOL Development: Early Identification

Many reasons exist to make sure a list of KOLs stays up-to-date, whether it is on the HCP side or the product space:
- HCPs may change position, move, retire…
- New indications may be approved or new competitive products may be launched.
In all cases, it is crucial to be able to anticipate any change and adjust the KOL strategy according to these changes.
This case study briefly depicts a situation where management wanted to validate the existing KOL ranking and more importantly identify opportunities to add “rising stars” to this list.
The context is a neurology space and the population under study consists of all neurologists in the country.
Project Objectives
Primary Objective
To identify potential new opinion leaders in the space under study.
Secondary Objective
To validate the current KOL list and determine if all are still as important as expected.
Main Project Steps

1. Lists
The first step is to ensure that there is a list of all HCPs to be included in the project, in this case all active neurologists.
A second crucial input is a validated list of reference KOLs.

2. Distinguishing Features of KOLs
At that step, the characteristics or features that are anticipated to potentially distinguish or could help distinguishing a KOL from a non-KOL are discussed.
The list established shall not yet be limited by data availability. It rather consists of having the client depicting what features in his/her opinion makes a neurologist a KOL for this specific application.

3. Data Sources
This is the time when the potentially abstract criteria established in the previous step start being translated into existing measures. For instance, as the research excellence was considered as a key criterion for being a KOL in this specific context, we needed to make sure that we could establish a reliable list of scientific publications for each neurologist.
More generally, the value of the data sources already available to the client is assessed and agreement is reached on any additional data that should be extracted/gathered/collected/generated.
In this project, several data sources were made available to us by the client: customer demographics, sales data for the market under study, as well as various call notes stored in the CRM.
Additional data sources were generated by us, some based on our validated Internet querying and scraping algorithms, others obtained by extraction of relevant scientific activity from medical databases.
4. Data Preparation/Cleansing
In the machine learning world, this step is often referred to as data engineering. It is by far the most crucial and time consuming phase of any ML-based project.
In order to harness the full potential of the raw data previously extracted, meaningful summaries need to be computed. Techniques such as text mining were used in order to convert CRM notes into quantitative features. Other adapted tools allowed computing a whole range of characteristics for each HCP.
Another essential aspect of that step concerns the validation of the data. Whether the information was obtained from the Internet or from scientific databases, we needed to make sure that each piece of it was related to the right HCP.
Last, note that even though this stage tries to reconcile the existing data with the theoretical features identified during the second stage, no subjective selection shall be made and the set of potential features shall be kept as large as possible.

5. Data Integration
Machine learning is used to integrate, investigate and to generate a predictive model aimed at estimating HCP influence scores.
During this process, several algorithms are compared and fine-tuned to determine which best fits the available data. It is important to keep in mind that all potential features identified and computed in the previous steps are left free to be used and weighted as needed by the algorithms. None are forced in or out or overweighted.
Last but not least, the practical value of the retained model is assessed on the one hand by its capability to discriminate between KOLs and non-KOLs, and on the other hand by making sure that the main model drivers make sense and are consistent with the original expectations (stage 2).
A model should NEVER be used without knowledge of its performance and potential limitations.

6. Influence Score Estimation
Once the model has been finalised and validated, the full set of neurologists is passed through the algorithm to compute a score of influence.
This yields for each neurologist a value between 0 and 100 where a higher value means more influence according to the retained criteria.

7. Influence Score Delivery
Estimated influence scores are typically delivered in the form of an EXCEL file with as many rows as the initial number of HCPs in the list provided by the client.
On top of that, a document presenting the model validation, its limitations if any and more generally its scope of use is also presented.
Interpreting Influence Scores
In order to illustrate the outcome of this specific project, a simple visual tool may be used. It consists of plotting each neurologist according to his/her original group (KOL vs. non-KOL) against his/her computed influence.
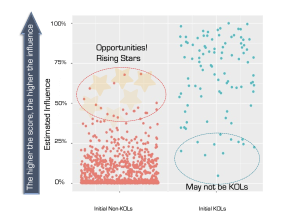
The plot first shows that the approach allowed a pretty good discrimination of KOLs (which was one of the goals of model validation). It is also possible to see that a few neurologists within each group tend to deviate from the trend: higher influence for some non-KOLs and lower influence for a few KOLs.
The former are the natural candidates for being rising stars while one should determine whether the latter should still be considered as KOLs for the context of this project.
Going Further With this KOL Tool
Once the process has been put in place, it becomes rather easy to maintain and reuse on a yearly basis for instance. It is only needed to update the list of HCPs and the data sources, and then process them through the data engineering algorithms and the ML model.
This allows and easy update of the KOL universe for a given context and can also help establishing a long-term monitoring of the influence of each HCP.