



Insights on GPs |
 |
| Clinical Interests |
| Social Media Usage |
| Research Activities |
| Online Self-Promotion |
| Biography |
| Quality of Care |
| … |
Covers almost any publicly available information on the Internet |
Regular updates to keep pace with GPs evolving web profiles |

Insights on Practices |
 |
| Use of Digital Technology: online bookings, digital content, blogs, website complexity |
| Online Repeats |
| Availability of Allied Health |
| Business Hours, Bulk Billing |
| Languages Spoken |
| … |
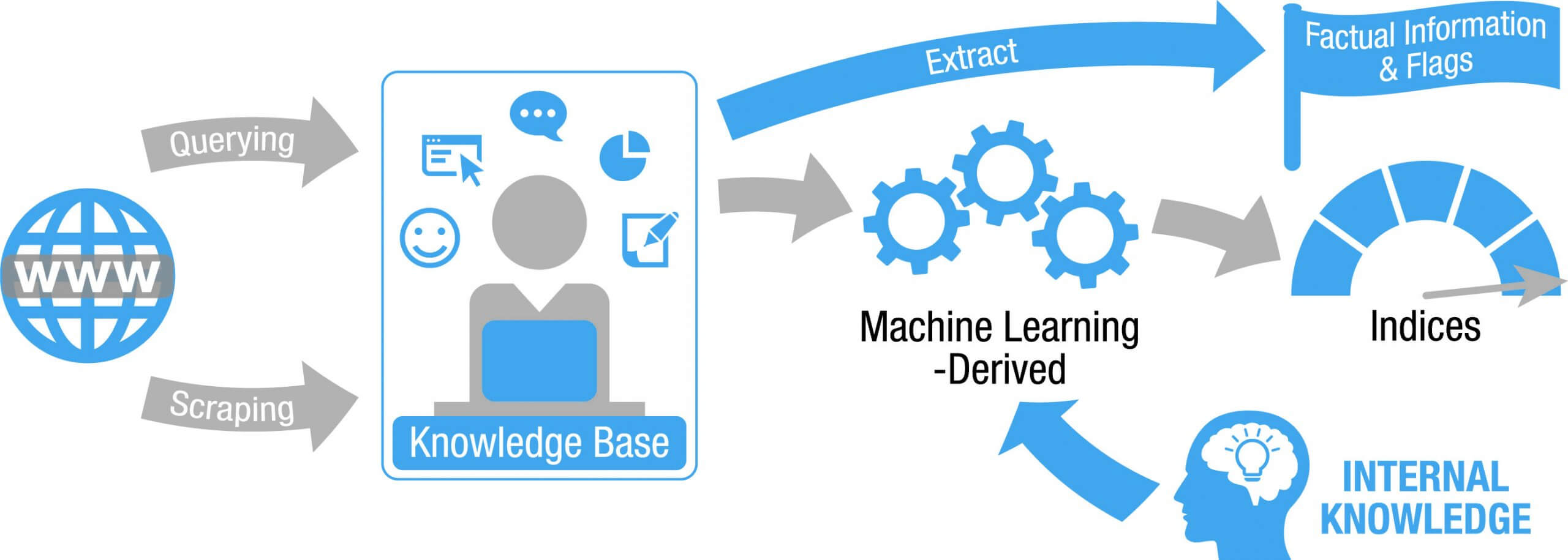

Web Querying |

| A method of extracting information from the internet using keywords in a search engine, e.g. Google or MS Bing. |
Web Scraping |  |
A method of extracting information from relevant websites. Scraping goes far beyond querying. Internet query may be used to identify websites for scraping. The depth of information scraped can include, Drs. interests, number in the practice, practice email, fax no., online bookings, bulk billing, car parking, etc. Large number of individual features or characteristics can be scraped in this manner. On their own some may seem irrelevant, but when combined and incorporated into the machine-learning algorithm, each feature and their complex relationships can add to the profile. | |
Data Engineering – Extensive Data Validation & Cleansing |  |
Over the years we have put in place complex data matching, duplicate identification, validation & cleansing algorithms to make sure that we correctly identify HCPs and that we extract relevant and consistent information.
Generating New Features |  |
Using our knowledge of pharma & the business problem at hand, we also generate additional features based on the raw information extracted from queries & scraping results.
For research activities, we typically calculate the median authorship position for medical publications. The position in the list of authors may be used as a proxy for influence. We typically generate hundreds such features.
Machine Learning Based Data Aggregation |  |
Typically results are aggregated into an index or score e.g. social networks – a higher score assigned where the search indicates high engagement with social networks.
The nature of the indices depends on the goal of the application, e.g. predicting potential, influence, early adoption, digital proficiency, digital engagement, etc.